[실습] 정보의 처리 : 2024 LCK
1. lck_2024.csv 파일을 데이터프레임으로 로드하여 다음 작업 진행
'팀' 컬럼으로 인덱스를 수정
내 코드>
import pandas as pd
df_gm = pd.read_csv('data/lck_2024.csv', encoding = 'cp949')
df_g1 = df_gm.set_index('팀')수정 코드>
import pandas as pd
df_gm = pd.read_csv('data/lck_2024.csv', encoding = 'cp949')
df_gm
df_gm.columns
Index(['이름', '팀', '포지션', '월즈우승', 'lck우승', '나이', '데뷔년도', '리그경기수', '리그승률',
'리그KDA', '서머승률', '서머KDA', '리그킬관여율', '서머킬관여율', '반려동물 유무'],
dtype='object')
df_gm = df_gm.set_index('팀')
df_gm▷ 인덱스를 확인하고 수정하는 방법도 좋은 것 같다
2. 컬럼 이름 수정
'lck우승' => '리그우승',
'나이' => '만 나이'
df_gm = df_gm.rename({'lck우승':'리그우승', '나이':'만 나이'}, axis=1)
df_gm▷ axis 설정하는 것 잊지 말기
3. '서머킬관여율'에서 결측치인 관측치는 제거
내 코드>
df = df_gm.dropna(subset='서머킬관여율')
df수정 코드>
df = df_gm.dropna(subset='서머킬관여율')
df.isna().any(axis=0)
이름 False
포지션 False
월즈우승 False
리그우승 False
만 나이 False
데뷔년도 False
리그경기수 False
리그승률 False
리그KDA False
서머승률 False
서머KDA False
리그킬관여율 True
서머킬관여율 False
반려동물 유무 True
dtype: bool▷마지막에 isna()를 통해 확인 작업까지 추가함
4. '리그킬관여율', '서머킬관여율'에서 결측치를 각 컬럼의 평균으로 채우기
내 코드>
mean= df_gm[['리그킬관여율', '서머킬관여율']].mean()
df_gm.fillna(mean)
df_gm수정 코드>
mean = df_gm[['리그킬관여율', '서머킬관여율']].mean()
df_gg = df_gm.fillna(mean)
df_gg[['리그킬관여율', '서머킬관여율']].isna().any(axis=0)
리그킬관여율 False
서머킬관여율 False
dtype: bool▷ mean은 시리즈이기 때문에 fillna()에 그대로 넣기 가능.
▷ isna()를 통해 결측치 확인작업 추가
5. '서머킬관여율'의 결측치는 '서머승률' * '서머KDA'/5 로 채우고 '반려동물 유무'의 결측치는 0으로 채우기
내 코드>
sk = df_gm['서머승률']*df_gm['서머KDA']/5
df_gm = df_gm.fillna({'서머킬관여율':sk, '반려동물 유무':0})
df_gm
수정코드>
df1 = df_gm.fillna({'서머킬관여율':df_gm['서머승률']*df_gm['서머KDA']/5,
'반려동물 유무':0})
df1[['서머킬관여율','반려동물 유무']].isna().any(axis=0)
서머킬관여율 False
반려동물 유무 False
dtype: bool▷나는 새로운 변수로 설정했는데, 풀이에선 바로 연산을 추가해서 더 간편한 코드가 나온 것 같다.
6. '반려동물 유무'의 값을 0=>'없음', 1 => '강아지',2 =>'고양이' 로 변경
내 코드>
df_gm['반려동물 유무'] = df_gm['반려동물 유무'].replace({1:'강아지',2:'고양이'})
df_gm수정 코드>
df1['반려동물 유무'] = df1['반려동물 유무'].replace({0:'없음', 1:'강아지',2:'고양이'})
print(df1['반려동물 유무'].unique())
['없음' '강아지' '고양이']▷데이터타입을 바꿔서 깔끔하게 수정
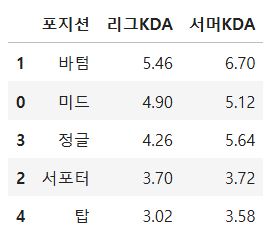
7. '포지션' 그룹화 하여 '리그KDA', '서머KDA'의 평균을 구하고 리그KDA로 내림차순 정렬하여 출력
내 코드>
df_gp = df_gm.groupby(by='포지션')[['리그KDA','서머KDA']].mean()
df_sort = df_gp.sort_values('리그KDA', ascending=False)
df_sort풀이코드>
df_gb = df.groupby(by= '포지션', as_index=False)[['리그KDA','서머KDA']].mean()
df_sort = df_gb.sort_values('리그KDA', ascending=False)
df_sort▷groupby 옆에 as_index=False 넣어줌
8. '반려동물 유무'컬럼과 '포지션'컬럼으로 그룹화 하여 리그승률의 평균을 피벗 테이블로 표현
내 코드>
pivot = pd.pivot_table(df1, index='반려동물 유무',
columns = '포지션',
values = '리그승률',
aggfunc = 'mean')
pivot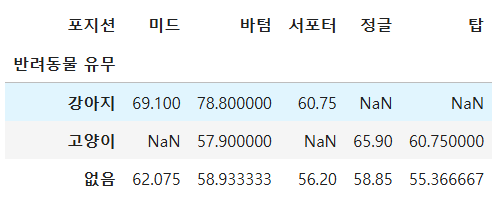
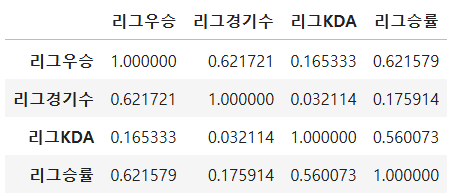
10. '리그우승','리그경기수','리그KDA','리그승률' 의 관계를 피어슨 상관계수 표로 표현
내 코드>
df_gm[['리그우승','리그경기수','리그KDA','리그승률']].corr()